In normal circumstances, learning processes play a fundamental role in how we respond to threatening or harmful states (including pain), by allowing us to avoid or minimise harm. For instance, after injury, adaptive learning processes occur at all levels of the nervous system and tune behaviour to optimise recovery. In the brain, changes in motivation (i.e. value-based learning and decision making) manifest as increased avoidance and a reduced tendency to seek rewards/relief, explore alternative solutions and energy conservation (Seymour, 2019). At the same time, sensorimotor learning allows us to adapt our movements and learn those that aid protection of the injured region (Hodges and Tucker, 2011). These processes work together with central sensitisation of the spinal dorsal horn and peripheral nociceptor hypersensitivity to drive protective responses to the injured region, which is likely to be hyper-susceptible to further injury (Woolf and Salter, 2000). Together, these processes have evolved to adapt behaviour in a way that is precisely tuned to the injury.
Value-based and sensorimotor learning can be quantified and studied using computational models of learning in the brain (Seymour and Mancini, 2020), offering a mechanistic account of how specific neural circuits drive behaviour in response to pain and injury. A key insight from these models is an understanding of how this leads to direct modulation and amplification of pain through endogenous control circuits, illustrating how the brain acts as the core control center for pain and behavioural homeostasis (Heinricher et al, 2009).
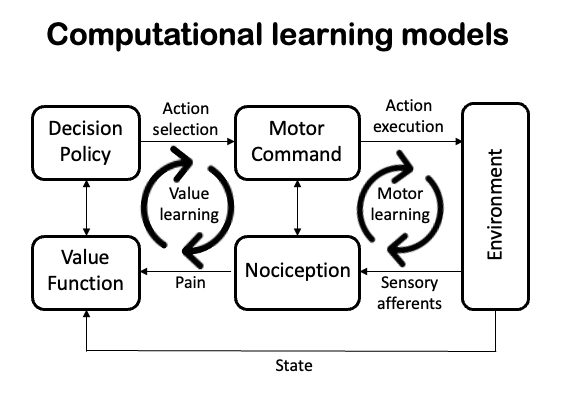
This theoretical framework predicts that misaligned or maladaptive learning might lead to dysfunctional endogenous pain regulation – either independently; by interacting with coincident ‘maladaptive’ processes at a peripheral or spinal level (Arendt-Nielsen, 2015; Woolf, 2011); or indirectly as in the fear-avoidance model (Vlaeyen et al., 2016). This idea is attractive because it offers consilience between peripheral and central ‘theories’ of chronic pain, whilst accommodating biopsychosocial determinants (Mansour et al, 2014). It would also explain comorbidity with anxiety and depression through shared susceptibility in value-based learning. And importantly, it would reveal precise targets for therapeutic intervention via behavioural and technology-based approaches that are specifically targeted to modulate learning. Our team is testing this idea in a research program funded by UKRI.
We have chosen three validated learning paradigms to assess learning to avoid losses. These paradigms incorporate the spectrum of different types of learning that underlie domain-general value-based and sensorimotor learning:
Instrumental learning task (pop a balloon game)
This is a three-alternative choice probabilistic instrumental (operant) learning with mixed, non-stationary, independent rewards/losses (3-armed bandit task). On each trial, subjects choose which balloon to pop and observe outcome (reward, loss), which changes over time. The task assesses reward and punishment sensitivity, exploration, learning/forgetting rates, and attention, and is modelled with reinforcement learning algorithms (Seymour et al., 2012). The task is validated in clinical cohorts (Aylward et al., 2019; Seymour et al., 2016), and engages classic reward and punishment areas (striatum and medial prefrontal cortex).
Generalization task (stay safe game)
Here, players learn to avoid hidden punishments based on visual cues (‘signs’). Safety signs and danger signs look very similar, but differ subtly in visual features (Norbury et al., 2018). The task, validated online, tests how people generalise from known examples of signs, and key outcomes measures are punishment and safety generalisation, based on models of avoidance and perceptual learning. The task engages amygdala, striatum and insula (Onat and Büchel, 2015).
Motor learning task (hit the target game)
Subjects try to touch on the tablet screen a rewarding circle and avoid an overlapping penalty circle in order to win as many points as possible given the time period. This task probes motor learning in terms of response accuracy and variability, as well as sensitivity to reward and loss (Kurniawan et al, 2010).
All games have been developed in partnership with member of the public and people with lived experience of pain, during which we have cycled through initial iterations to optimise the user interface, game environment, playability and difficulty, and levels of engagement. Statistical optimisation is run in parallel with gamification, based on computational models of learning estimated using a hierarchical Bayesian model fitting procedure.